
Web Scraper Technology
We have developed our own powerful web scraper technology as a part of our portal solutions. It has been used for a long time in our portals in real-time mode. Surely we can use it for your tasks.
As the technology is ready, we don’t need to spend a lot of time writing it from scratch. All we need is to write plugins for source sites and for each output format.
It will drastically reduce the project term and save the costs.
This scraper can collect different data and store it to a customized target format (like CSV or Excel).
The technology is mature and highly customizable, it has its own database with history of already scraped data that allows reconciling the data; checking history of the data which were scraped and version history of each entity spidered; checking if similar data already exist and so on.
Technology possibilities:
EASY SUPPORT OF NEW SOURCE SITES
You can easily add new sources for the scraper. For each new source the programmer will write a plugin. So, the scraper can be updated easily, rapidly and cost effectively to support new sources of data. For example, if it is a scraper for news, it can take news from different sites, but aggregate them into the same output format (db, excel or csv)
EASY SUPPORT FOR DATA OUTPUT
You can define how to store data. You can store data to multiple locations in different formats. Data from all inputs are stored in one output format and mixed together
ENTITY DESCRIPTION
For each entity you scrap you can define attributes via UI for further per attribute configuration (in blacklist)
BLACK LIST
Rules which source data should be omitted from the scraper. For each field of source data black list rules can be configured. If an attribute of a source entity contains black list data for such an attribute, the entity will be omitted.
CHECKING FOR UPDATES (reconciliation)
Checking of previously uploaded data: if updates happen in source entities, target entities will be overwritten (new row will not be added, but it will be overwritten instead). If source entities were deleted, target entities will be deleted too. If there are new source entities, they will be added to the target dataset.
VERSION HISTORY
History of each row versions (in case of updates) is stored. Web-interface of history exists. It works in case of checking for updates capability.
SCRAPER LOG AND OPERATIONS HISTORY
History of what and when have been scraped can be stored or omitted.
SIMILARITY CHECK
If text data are equal or similar (with a defined level of similarity), new source data can be omitted with logging such information into a log
ADMIN WEB INTERFACE
Web-interface where you can set parameters of start, define schedule, black lists, select modes, see version history and operations history etc. It supports a set of scrapers that can work in parallel.
CONFIGURABLE SCHEDULE
Schedule of the scraper is configurable and can run every week or due to your requirements.
MANUAL START
You can run the scraper manually or re-scrap a selected entity from the scraping history in the UI
Automatical content classification
We have technology of automatic classification of content. You can define directory of terms (including multi word terms), and input data will be automatically classified, and even related terms could be selected by tags.
For examle, for our medical portal. We have news that are crowled periodically. After crowling they are classified, and terms are hyperlinks to the term page.
For example: here is a list of terms in terms admin tool:
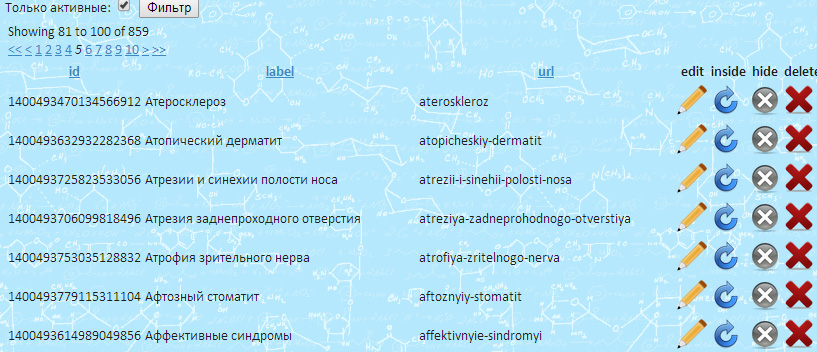
Here is a page with news, getted by scrapper and classified:http://www.med-life.com/news/pochemu-krayne-neobhodimo-kushat-morskuyu-ryibu-02042014
You can see hyperlinks in the text. They are automatically created. Also automatically news was classified us related to «Атеросклероз» (in cyrillic, sorry), and link to this term’s page was created under the news text. If you press on this link you can see the backreference link to this news from the term page.
Also you can see, we can classify also phrases, not only single words. You can see one two-word link — «рыбий жир».
Also you may see that not all of the links are reflected under the bottom of the news. It’s because of type of terms. We have terms of type «desease» and «substance». And we define different processing in dependence of what is the type of the term.
So, we can classify crowled content automatically, and do any actions on classified content.
Examples:
1) Scrapers for medical portal
Portal url: http://www.med-life.com/
This is a medical portal with news and medical information. News and medical instructions are scraped (two scrapers, as different types of entities)
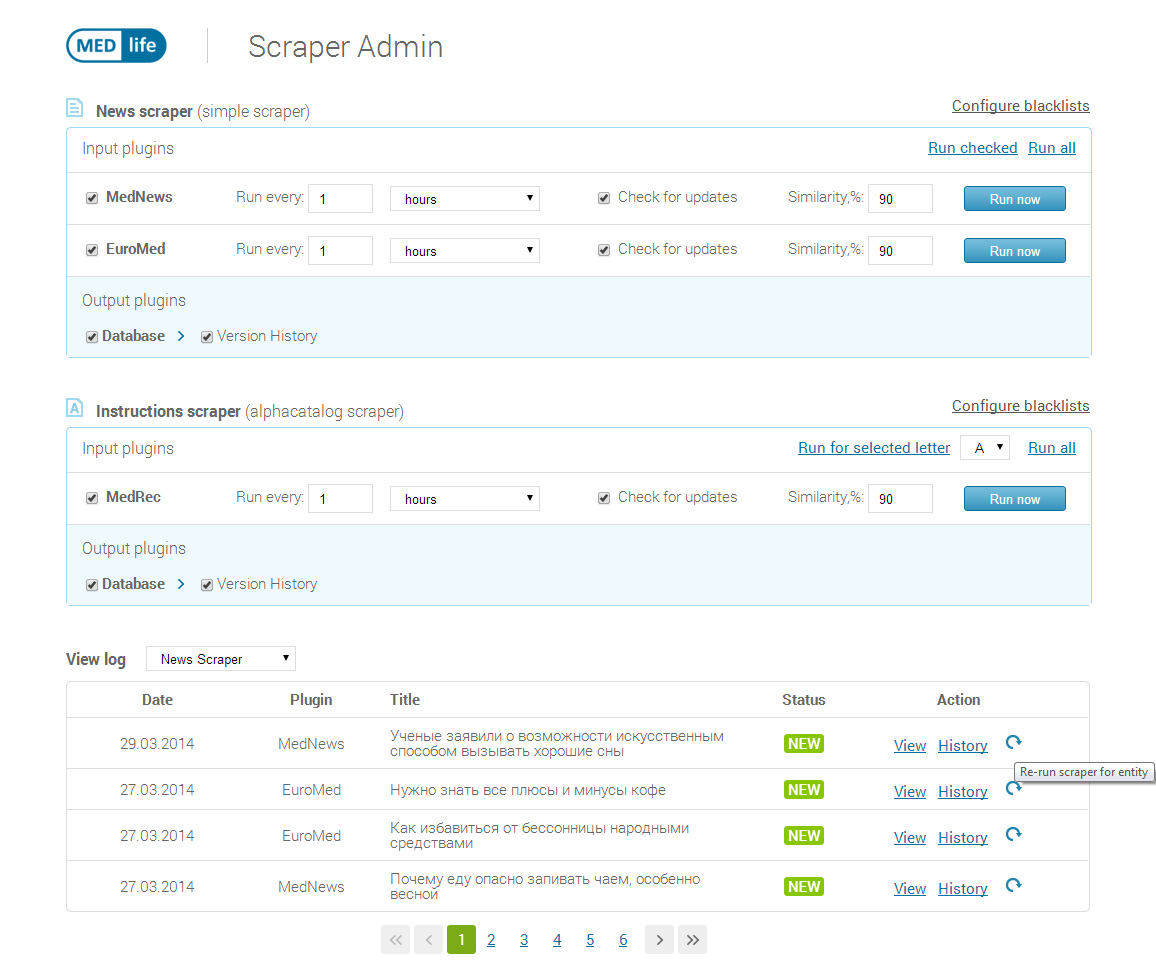
Features of the news scraper:
- News from 2 sources are scraped (look results at main page : http://www.med-life.com/)
- News are aggregated in the same table in the database (2 inputs stored to 1 output)
- As news can be similar for two sources, there is a similarity check.
- News from both sources are scraped each hour
- Black list: news at a source site sometimes has an «original site» field. There is a list of original sites the data from which are prohibited for scraping. Such news are omitted.
- News are updated if the source data have been changed (reconciliation)
- History of all versions for each entity is stored
- Log of scraped data is stored
- You can manually rescrap all or selected entities
- Supports list based (for news) and alphacatalog (for instructions) scrapers
Features of instructions scraper:
You can see the instructions scraped by this scraper at http://www.med-life.com/drugalphadir
This scraper is of alphanumeric type and intended for scraping alphabetic catalogs (in opposite to pagered list based source web data supported by previous scraper) with the ability to refresh by letter
2) Scraper for auto portal
Portal url: http://www.inautoclub.net/
Here you can see:
- news on the main page: http://www.inautoclub.net/
- hierarchy catalog scraped: http://library.inautoclub.net/carManufacturerList/
Terms and Cost
With such technology we can scrap up to 6 sites per day, depending on complexity of the data and site structure. We assume that the sites has a normal structure and data of one type stored in the same way. Otherwise estimation can differ.
So, for each source site we can estimate the required time before start and you will know the cost before.